
When people talk about Anthropic’s technology, the first question is often: why does Claude have so many names — Opus, Sonnet, Haiku — and what actually sets them apart? Dig a little deeper and an even more central term surfaces: Constitutional AI.
This piece walks through Anthropic’s technical path: how the model family divides the work, what makes its safety method distinctive, and which domains it deliberately avoids. What we’re covering here is the path and the design thinking, not specific version numbers — new versions keep shipping, but the underlying logic stays relatively stable. If you want to get to know the company first, start with What kind of company is Anthropic.
To set the tone in one line: Anthropic splits its models into three tiers to serve different needs, turns safety into a scalable method, and deliberately narrows its domain to text and code.
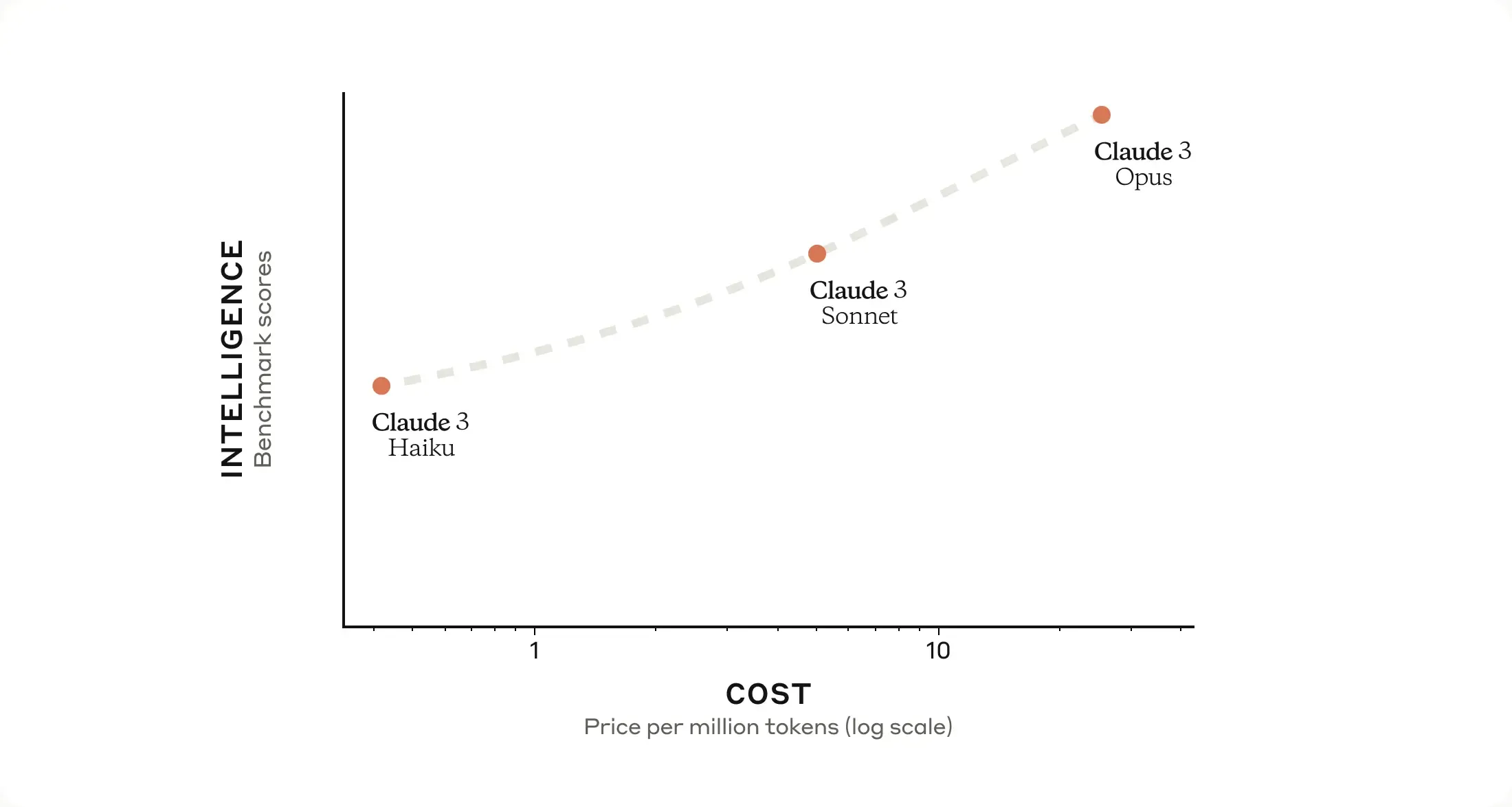
Three tiers: Opus, Sonnet, Haiku
Claude is actually a tiered family rather than a single model, using three names drawn from music and poetry to mark the levels:
- Opus: the strongest tier in the family, suited to complex tasks that need deep reasoning and long chains of thought. Reach for it on the hardest problems — though it also carries the highest cost and latency.
- Sonnet: the balanced path, striking a middle ground between performance and cost. It’s the day-to-day workhorse most enterprises and developers rely on, and the backbone of products like Claude Code.
- Haiku: built for low latency and low cost, fitting high-volume, lightweight tasks that demand instant responses.
The point of this tiered design is very practical: not every task needs the strongest model. Letting users pick a tier based on need helps them find the most cost-effective fit between performance and cost. The capabilities and positioning of the three tiers evolve with each new version, but the “strong / balanced / lightweight” division stays remarkably stable.
Directionally, the Claude family leads with long-context understanding and coding, and pushes toward “long context” and “agent capability” so the model can read large volumes of content, use tools in sequence, and complete multi-step tasks on its own.
Constitutional AI: letting the model fix itself
Anthropic’s most recognizable technical signature is a training method called Constitutional AI.

Traditional approaches often lean on heavy human effort, labeling responses one at a time — “this answer is good, that one isn’t” — to tune the model. Constitutional AI works differently: it first gives the model a human-written set of “principles,” something like a behavioral constitution, and then lets the model critique and revise its own responses according to those principles.
This brings two benefits. The first is scalability: guiding the model to self-correct through principles is more efficient than relying purely on human labeling. The second is transparency: that set of principles is written down, so outsiders can more readily discuss “what this model is being asked to follow.” For a company that treats safety as its signature, building safety guidelines in at the training stage — rather than patching them after something goes wrong — is the core of its technical philosophy.
Of course, whether the constitution is well written and whether the model actually follows it remain questions that need ongoing scrutiny, which also ties into the company’s public safety commitments and its Responsible Scaling Policy.
Interpretability: trying to understand what the model is thinking
Beyond Constitutional AI, Anthropic’s other research signature is interpretability.
Put simply, this field aims to understand what’s actually going on inside the model: when Claude produces a response, how its internal neural network operates and why it judges the way it does. This is harder than simply testing the model’s external behavior, yet Anthropic sees it as the necessary path to genuine safety. Its logic is this: only by understanding the inside of the model can you foresee and correct errors before they happen, instead of putting out fires after the fact.
This line of research has earned Anthropic considerable credibility in academia and industry, and has become an important pillar of its brand narrative that “safety is for real, backed by research.”
The things it deliberately doesn’t do
To understand a company’s technical path, looking at what it doesn’t do is often as telling as looking at what it does.
Anthropic explicitly stays away from image generation, video generation, and hardware devices. While rival OpenAI spreads its product line wide and varied, Anthropic chooses to concentrate its resources on text, code, documents, and enterprise workflows. This narrowing is strategy, not inability: going as deep as possible on its chosen battlegrounds — to the point of being hard to replace — beats scattering resources to dabble in everything. For how the two companies’ paths compare, see Anthropic vs OpenAI.
From chat to enterprise: how the models become products
The same Claude models reach different users in different forms:
- Consumers: through the Claude.ai website and app, with free and paid plans.
- Developers: through the Claude API and Claude Code, wiring the models into their own applications and development workflows.
- Enterprises: team and enterprise plans, paired with security and management features.
- Cloud channels: also listed on the AI platforms of AWS, Google Cloud, and Microsoft, so enterprises already on those clouds can access Claude close at hand.
On top of that, Anthropic has driven an open protocol called MCP (Model Context Protocol), which makes it easier for Claude to connect to external tools and data sources — turning itself into part of the developer ecosystem rather than an island.
Penchan’s take
String Anthropic’s technical path together and it turns out to be remarkably consistent: the models split into three tiers so different needs can each find the most cost-effective option; Constitutional AI and interpretability turn “safety” into something methodical and research-backed rather than just marketing talk; and deliberately staying out of images and hardware puts limited resources on the battlegrounds it’s most confident in.
The biggest bet in this path is the belief that “safe” and “useful” can run in parallel — that the former can even become a selling point for the latter. For enterprise customers, a model whose behavior is predictable and whose workings are explainable really is a key consideration at adoption time. That’s exactly what Anthropic is betting on, and its technical choices all revolve around this conviction.
Further reading: What kind of company is Anthropic, How Claude Code became a growth engine, Why Anthropic is a public benefit corporation.