
5 月 28 日、Anthropic は Claude の主力モデルを Claude Opus 4.8 へとアップグレードしました。
モデルのアップグレードは定期的にやってくるもので、たいていは私もそのままスルーします。でも今回は、立ち止まって 1 本書こうと思える理由が 2 つありました。1 つ目は、agentic な能力が明らかに安定し、仕事ができるようになったこと。2 つ目は、Claude Code の中で Dynamic Workflows を開放し、一度に何百ものエージェントを同時に働かせられるようになったこと。これはまさに、私がこの 2 年ずっと取り組んできたマルチエージェント路線そのものなのです。
先に透明性のための前提を 1 つ。小企鵝の普段の AI 相棒(つまり原稿執筆やファクトチェック、ファイル整理を裏で手伝ってくれている基盤モデル)も、この 2 日で Opus 4.8 へとアップグレードされました。なので、この記事はある意味、彼自身が自己紹介しているようなものなのです。😅
今回のアップグレード、注目はこのあたり
| ポイント | ひと言で |
|---|---|
| 能力の全面強化 | agentic な判断がより安定し、コードを書くときに未注記のエラーを残す確率が 4.7 より約 4 倍少なく、ツール呼び出しもより速く正確に。computer-use(ブラウザやパソコンを直接操作する機能)は Online-Mind2Web で 84% を獲得し、現時点で最強 |
| Dynamic Workflows | Claude Code の新機能:Claude が自分で計画し、一度に数十から数百の並列エージェントを立ち上げ、検証を通してから報告する(この記事の後半に私の実演あり) |
| より誠実 | 詰まったときは自信がないとそのまま言い、無理に進展を報告しない。公式は「現時点で最も誠実」なモデルだと打ち出している |
| 価格は据え置き | 4.7 と同価格(入力は 100 万トークンあたり 5 ドル、出力は 25 ドル)、Fast モードはさらに速く安い |
ひと言でまとめると:同じ値段で、より仕事ができて、より正直な頭脳に乗り換えられる。一般ユーザーにとって一番ダイレクトなメリットは、何も変える必要がなく、claude.ai や Claude Code のモデル選択メニューで Opus 4.8 を選ぶだけ、ということです。
能力の強化:判断がより安定し、コードがよりきれいに、しかも自分でパソコンを操作する
今回いちばん実感のある進歩は「作業の信頼性」です。公式の評価によると、Opus 4.8 がコードを書く際に未注記の欠陥を残す確率は、4.7 より約 4 倍少なくなりました。agentic なタスクでの判断もより安定し、ツール呼び出しもより速く正確になっています。computer-use(AI に直接ブラウザやパソコンを操作させる、あの種の機能)も現時点で屈指の強さです。
Anthropic は公式に 1 枚の対照表を出して、話をよりはっきりさせています:
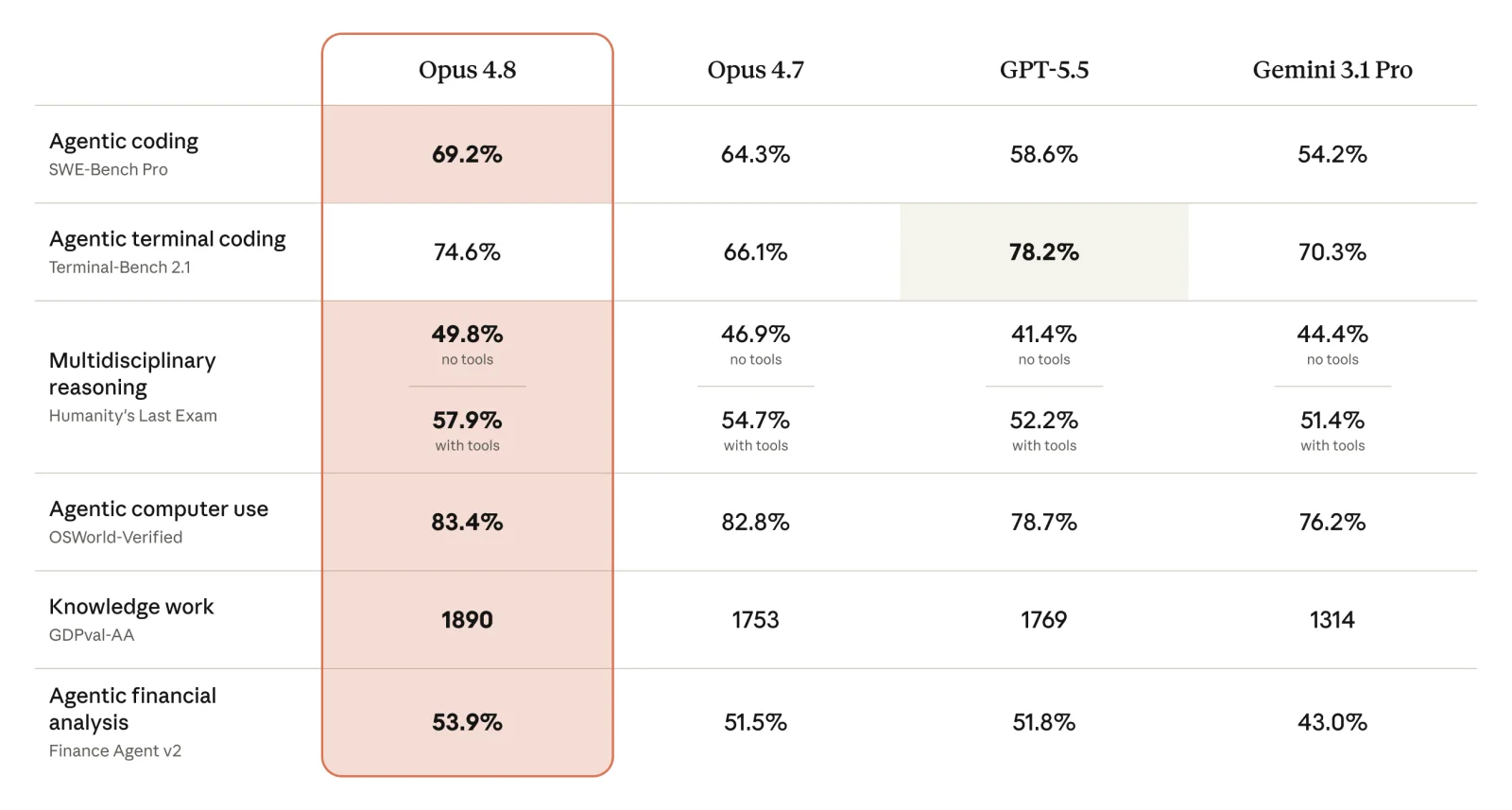
表では Opus 4.8 を自社の 4.7、GPT-5.5、Gemini 3.1 Pro と比較しています。Opus 4.8 は agentic なコーディング(SWE-Bench Pro 69.2%)、パソコン操作(OSWorld-Verified 83.4%)、ナレッジワーク(GDPval-AA 1890 点)、金融分析のいずれにおいても 4.7 を一段リードしています。とはいえ、負けている項目もあります。ターミナルでのコーディング(Terminal-Bench 2.1)では、GPT-5.5 の 78.2% が Opus 4.8 の 74.6% を上回りました。勝つところは勝ち、負けるところもありのままに記す。この点はちょうど、打ち出している「誠実さ」と呼応しています。
この中で私が最も重視するのは「誠実さ」です。ひとまとまりの仕事を AI に丸ごと走らせるとき、本当に怖いのは「知ったかぶり」です:本当は終わっていないのに自信たっぷりに「できました」と言い、コードに bug を埋め込んでいるのに堂々と書いて、一言も触れない。Opus 4.8 が変えたのはまさにこの点で、詰まったときに「ここは自信がありません」とより進んで言うようになり、証拠が不十分なときに無理やり進展があったと言ったりしません。だからこそ複数のメディアが、これを Anthropic「現時点で最も誠実」なモデルと評しているのです。
これは抽象的に聞こえますが、実際にタスクを外に振る人にとっては非常に実感のあることです。詰まったときに「自信がありません」と手を挙げてくれるアシスタントは、いつも「全部できました」と返してくるアシスタントよりはるかに使いやすい。どこを見直すべきかが分かるからです。
effort と ultracode:古い機能が 1 つ、新しいスイッチが 1 つ
effort(力の入れ具合)という概念は、実のところ新しくありません。Claude Code の長年のユーザーなら xhigh に馴染みがあるはずで、これは Claude が 1 つの問題にどれだけ力を使うかを決めます。4.8 はこれをより明確に整理しました:claude.ai 上でも直接調整でき、デフォルト(high)、extra(Claude Code では xhigh)、max の 3 段階に分かれます。覚え方はシンプルです。簡単なことは下げてトークンを節約、難しいことは上げて品質を取る。
本当に新しくて、いちばん面白いのが ultracode です。effort メニューでこれをオンにすると、自動で effort を xhigh に設定し、いつ後ほど説明する Dynamic Workflow を動員すべきかを Claude 自身に判断させます。次のこの動画は、それが Claude Code の中で実際に走っている様子です:
本当の切り札:Claude Code の Dynamic Workflows
モデル本体が「より仕事ができる頭脳」だとすれば、Dynamic Workflows は今回いちばんワクワクさせられた「新しい手足」です。
まず、それが何をするものなのか、かみ砕いて説明します。これまで Claude に仕事を頼むときは、1 つの AI が最初から最後までやり通す形でした。Dynamic Workflows は、Claude がまずあなたのニーズを理解し、自分で「分担スクリプト」を立て、それから一度に数十から数百の並列エージェントを立ち上げて、仕事をブロックに切り分けて同時に処理させます。さらに面白いのは、異なるエージェントに異なる角度から切り込ませ、お互いの粗をつつき合わせ、答えが収束するまで反復させる点です。そして検証を通してから初めて、結果をあなたに返します。途中で中断しても進捗を自動保存するので、最初からやり直さずに続きから走らせられます。
CyberAgent のエンジニアは、これをとても的確に言い表していました:これはちょうど「エージェントを 1 つ放り出す」のと「エージェントのチームを丸ごと自分で組む」のとの間にあった空白を、ぴったり埋めてくれる、と。
では、どれくらい大きな仕事ができるのか?公式が挙げた例は、Bun(ある JavaScript runtime)のコアを Zig から Rust へ書き換えたもの:75 万行のコード、11 日、既存のテストスイートを 99.8% 通過、です。その他の典型的なシナリオには、ファイルをまたいだ大規模なコード移行、サービス全体の bug 探しとセキュリティ監査、誰も使っていないデッドコード(dead code)の洗い出しなどがあります。
いくつか現実的な点を先にはっきりさせておきます:
- どのプランで使えるか:Max、Team、Enterprise で開放(Enterprise はデフォルトでオフなので、管理者が設定で有効化する必要があります)。また API、Amazon Bedrock、Vertex AI、Microsoft Foundry でも利用できます。現在は research preview(リサーチプレビュー) です。
- トークンをかなり消費する:使用量は通常の会話より明らかに多くなります。公式は、まず範囲が明確な小さなタスクから始めて感覚をつかむことを推奨しています。
- どうやって始めるか:2 つの方法があります。1 つは Claude に直接「workflow を 1 つ作って」と頼む方法。もう 1 つは effort メニューで
ultracodeをオンにし、いつ動員すべきかを自分で決めさせる方法です。初回の起動時には、まず確認を求められます。
実演:一文で、30 個のエージェントが私の 300 個の設定ファイルを改修
機能の説明だけだと抽象的すぎるので、昨夜自分で走らせた 1 ラウンドをそのままお見せします。
私の OpenClaw のコア設定ファイル一式(ルール、canon、各種 workflow ドキュメント)は長年、中国語と英語が混在していました。ずっと全部英語に統一したかったのですが、300 以上のファイルを 1 つずつ手で直すなんて、考えただけで頭が痛い。そこで今回、Opus 4.8 の Dynamic Workflow を使って試してみました:目標を一文で説明しただけで、Claude は計画を終えると一度に 30 個の並列エージェントを立ち上げ、300 以上のファイルを分担して同時に改修し、自分で検証して収束させたのです。
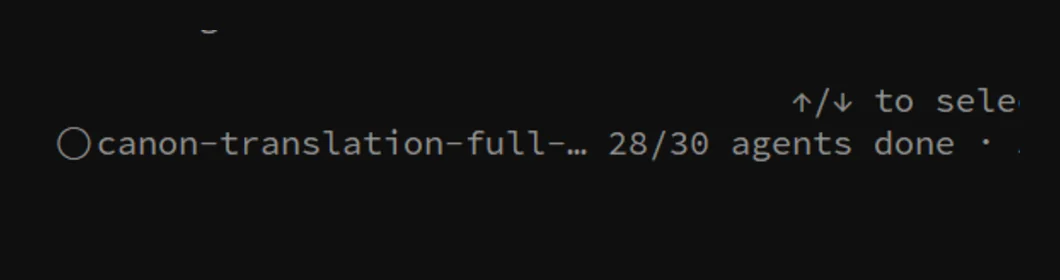
上のこの 1 枚が、まさに走っている途中の様子です:canon-translation という workflow で、30 個のエージェントのうちすでに 28 個が完了しています。これを手作業でやれば私の午後がまるまる 1 つ消える仕事ですが、今回はお茶を一杯飲むくらいの時間で片付いてしまいました。
正直なところ、一文で「300 個のファイル、30 体の分身が同時に処理」を起動できるのは、以前ならスクリプトを山ほど書かないと無理でした。とはいえ、私はこれを全自動として扱うつもりはありません。並列エージェントもやはりミスをするので、最後はもう一度別のモデルファミリーでクロスレビューするのが私の習慣です。自分で自分を審査して、問題を見落とさないように。
もう 1 つ、その場で確認した面白い点があります。これは「何層にも」積み重ねられるのです。Claude が計画して並列エージェントを一群立ち上げ、そのエージェントたちがさらにもう 1 層下へ、別ファミリーのモデル(GPT/Codex)を偵察役として呼び出し、裏取りをさせます。つまり 1 つのワークフローの中に、何層ものエージェントが、別々のモデルファミリーをまたいで分担しているのです。

一般の人がいま始められること
- より良いモデルを使いたいだけ:何もする必要はありません。claude.ai か Claude Code のメニューで Opus 4.8 を選ぶだけで、価格は以前と同じです。
- Dynamic Workflows を試したい:Max、Team、Enterprise のいずれかのプランが必要です。小さくて明確なタスクから始めましょう(たとえば「このフォルダの中で参照されていないファイルを全部洗い出して」など)。まずはどう分担するのか、どれくらいトークンを使うのかをしっかり見極めてください。
- effort の選び方が分からない:日常はデフォルトのままで OK。難しい問題に出くわしたら、ひとつ上げてみましょう。Claude に自分で加減を任せたいなら、ultracode をオンにします。
小企鵝のまとめ
今回のアップグレードで本当に心を動かされたのは、その方向性です:「誠実さ」を前面に打ち出し、なおかつ「一人で AI の群れを指揮する」ということを、ターミナルの中で一文で起動できる日常へと変えてくれました。
私が覚えておきたい一文はこれです:物事を AI に任せる時代において、「自信がない」と言える勇気のあるモデルは、いつも自信たっぷりなモデルよりずっと価値がある。 Dynamic Workflows については、これからも自分のシステムをモルモットにして、もっと多くの落とし穴を踏んだら、またここで皆さんにシェアします。
まずは足元のツールを固めたいなら、Claude Code 完全ガイドから始めるのがおすすめです。「一人で複数の AI をどう指揮するのか」が気になるなら、私がまとめたマルチエージェント編成の知見をどうぞ。