
5 月 28 日,Anthropic 把 Claude 的主力模型升上了 Claude Opus 4.8。
模型升級每隔一陣子就來一次,多數時候我會直接跳過。這次我停下來寫一篇,是為了兩件事。一是它在 agentic 能力上明顯更穩、更會做事;二是它在 Claude Code 裡開放了 Dynamic Workflows,可以一次指揮上百個 agent 同時幹活。這正是我這兩年一直在玩的多 agent 路線。
先講個透明的前提:小企鵝平常那位 AI 夥伴(也就是幫我跑稿、查證、整理檔案的底層模型),這兩天也跟著升上了 Opus 4.8。所以這篇文章某種程度上,是它在介紹自己。😅
這次升級,重點看這幾個
| 重點 | 一句話 |
|---|---|
| 能力全面增強 | agentic 判斷更穩、寫程式時沒標註的錯誤比 4.7 少約 4 倍、工具呼叫更快更準;computer-use(直接操作瀏覽器、電腦)在 Online-Mind2Web 拿下 84%,目前最強 |
| Dynamic Workflows | Claude Code 新功能:Claude 自己規劃,一次開幾十到上百個平行 agent,驗證過才回報(本文後面有我的實測) |
| 更誠實 | 卡住會直接說不確定,不硬報進度;官方主打它是「目前最誠實」的模型 |
| 價格不變 | 跟 4.7 同價(輸入每百萬 token 5 美元、輸出 25 美元),Fast 模式還更快更便宜 |
一句話總結:同樣的錢,換到一顆更能做事、也更老實的腦袋。對一般使用者最直接的好處是,你什麼都不用改,在 claude.ai 或 Claude Code 的模型選單選 Opus 4.8 就好。
能力增強:判斷更穩、寫扣更乾淨、還會自己操作電腦
這次最實在的進步,在「做事的可靠度」。官方評測說,Opus 4.8 寫程式時留下沒標註瑕疵的機率,比 4.7 少了約 4 倍;agentic 任務裡的判斷更穩,工具呼叫也更快更準。computer-use(讓 AI 直接操作瀏覽器、電腦的那種能力)也是目前數一數二強。
Anthropic 官方放了一張對照表,把話講得更清楚:
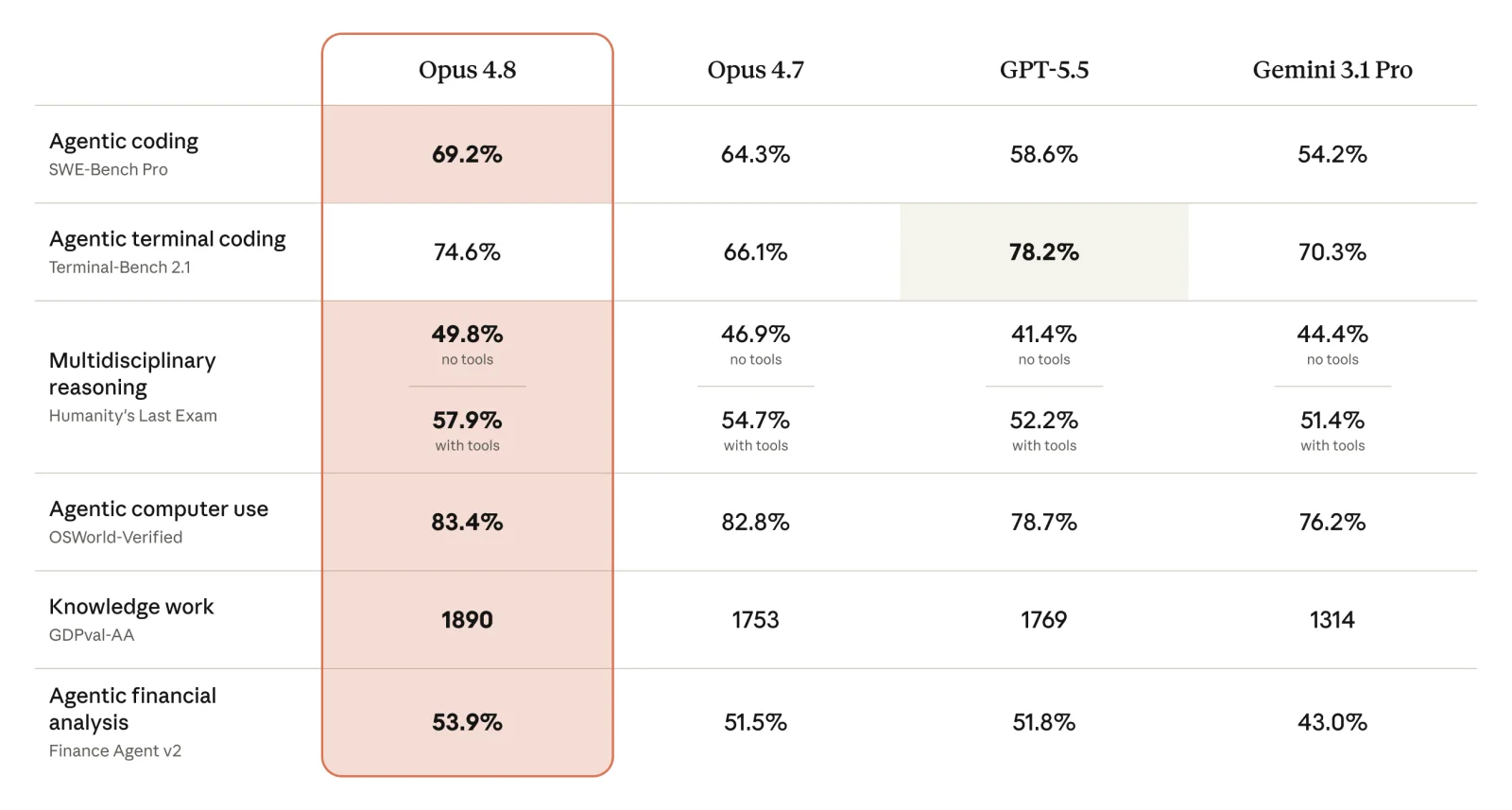
表裡拿 Opus 4.8 跟自家 4.7、GPT-5.5、Gemini 3.1 Pro 對比。Opus 4.8 在 agentic 寫程式(SWE-Bench Pro 69.2%)、電腦操作(OSWorld-Verified 83.4%)、知識工作(GDPval-AA 1890 分)和金融分析上都領先 4.7 一截。不過它也有輸的項目:終端機寫程式(Terminal-Bench 2.1),GPT-5.5 的 78.2% 就贏過 Opus 4.8 的 74.6%。贏的地方贏、輸的地方也照實標出來,這點剛好呼應它主打的「誠實」。
這裡面我最看重的是「誠實」。當你把整段工作交給 AI 自己跑,真正可怕的是它會「裝懂」:明明沒做完卻很有自信地說搞定了,程式裡埋了一個 bug,照樣寫得理直氣壯,一句都不提。Opus 4.8 改的就是這件事,它更願意在卡住時說「這裡我沒把握」,不會在證據不足時硬報進度。多家媒體因此把它形容成 Anthropic「目前最誠實」的模型。
這聽起來很虛,對實際把任務派出去的人卻超有感。一個會舉手說「我沒把握」的助手,遠比一個永遠回你「都好了」的助手好用,因為你知道哪裡該回頭檢查。
effort 與 ultracode:一個老功能,一個新開關
effort(用力程度)這個概念其實不新。Claude Code 老使用者對 xhigh 應該不陌生,它決定 Claude 要花多少力氣想一題。4.8 把它整理得更明確:claude.ai 上也能直接調,分成預設(high)、extra(在 Claude Code 裡就是 xhigh)、max 三段。簡單記,簡單的事調低省 token,難題調高拚品質。
真正新、也最好玩的是 ultracode。你在 effort 選單把它打開,它會自動把 effort 設到 xhigh,並讓 Claude 自己判斷什麼時候該動用後面要講的 Dynamic Workflow。下面這段就是它在 Claude Code 裡實際跑的樣子:
真正的大招:Claude Code 的 Dynamic Workflows
如果說模型本身是「更能做事的腦袋」,那 Dynamic Workflows 就是這次最讓我興奮的「新手腳」。
先用白話解釋它在幹嘛。以前你叫 Claude 做事,是一個 AI 從頭做到尾。Dynamic Workflows 則是讓 Claude 先看懂你的需求、自己擬一份「分工腳本」,然後一次開出幾十到上百個平行 agent,把工作切塊同時處理。更妙的是它還會讓不同 agent 從不同角度切入、互相挑彼此的毛病,一路迭代到答案收斂為止,驗證過後才把結果交還給你。中途斷掉也會自動存進度,可以接著跑而不用重來。
CyberAgent 的工程師把它形容得很精準:它剛好補上了「丟一個 agent 出去」跟「自己搭一整支 agent 團隊」之間的那塊空白。
那它能做多大的事?官方舉的例子是把 Bun(一個 JavaScript runtime)的核心從 Zig 改寫成 Rust:75 萬行程式碼、11 天、現有測試套件 99.8% 通過。其他典型情境包括跨檔案的大規模程式碼遷移、整個服務的 bug 獵捕與資安稽核、找出沒人在用的死碼(dead code)。
幾個現實要先講清楚:
- 哪些方案有:開放給 Max、Team、Enterprise(Enterprise 預設關閉,要管理員去設定裡打開),也走 API、Amazon Bedrock、Vertex AI、Microsoft Foundry。目前是 research preview(研究預覽)。
- 很燒 token:用量明顯高於一般對話,官方建議先從一個範圍明確的小任務開始抓手感。
- 怎麼開:有兩種方式。一是直接叫 Claude 幫你「建一個 workflow」;二是在 effort 選單打開
ultracode,讓它自己決定什麼時候動用。第一次觸發時會先問你確認。
實測:一句話,30 個 agent 翻修我 300 個設定檔
光講功能太空泛,給你看我昨晚自己跑的一輪。
我的 OpenClaw 整套核心設定檔(規則、canon、各種 workflow 文件)長年中英文混雜,我一直想全部統一成英文,但 300 多個檔案要一個個手改,光想就頭痛。這次我拿 Opus 4.8 的 Dynamic Workflow 來試:只用一句話描述目標,Claude 規劃完就一次開了 30 個平行 agent,把 300 多個檔案分下去同時翻修,自己驗證後收斂。
上面這張就是跑到一半的當下:canon-translation 這個 workflow,30 個 agent 已經完成了 28 個。手動處理大概要耗掉我一整個下午,這次差不多一杯茶的時間就收尾。
老實說,能用一句話啟動「300 個檔案、30 個分身同時做」,這在以前我得寫一堆腳本才辦得到。不過我不會把它當全自動:平行 agent 還是會出錯,最後我習慣再用另一個模型家族交叉審查一遍,免得它自己審自己、漏掉問題。
還有一個細節特別有意思,我當場問了一句確認:這套東西可以「多層」疊。Claude 規劃完開出一批平行 agent,這些 agent 自己又會再往下叫一層別家的模型(像 GPT/Codex)去當探馬查證。同一個工作流裡,等於疊了好幾層、還跨了不同家的模型在分工。

一般人現在能怎麼開始
- 只是想用更好的模型:什麼都不用做,claude.ai 或 Claude Code 的選單選 Opus 4.8,價格跟以前一樣。
- 想試 Dynamic Workflows:要 Max(或 Team / Enterprise)方案,從一個小而明確的任務開始(例如「幫我盤點這個資料夾裡所有沒被引用的檔案」),先看清楚它怎麼分工、會花多少 token。
- 不確定 effort 怎麼挑:日常維持預設就好,遇到難題再往上加一階;想讓 Claude 自己拿捏,就打開 ultracode。
小企鵝的總結
這次升級,真正打動我的是它的方向感:把「誠實」當成主打,又把「一個人指揮一群 AI」這件事,變成在終端機裡一句話就能啟動的日常。
我會記住的一句話是:把事情交給 AI 的時代,一個敢說「我不確定」的模型,比永遠很有自信的值錢得多。 至於 Dynamic Workflows,我會繼續拿自己的系統當白老鼠,跑出更多坑再回來跟你分享。
想先把底層工具打穩,建議從 Claude Code 完整教學 開始;對「一個人怎麼指揮多個 AI」好奇,可以看我整理的 多 agent 編排心得。