
AI Agentをしばらく運用すると、こんな状況に出会います。自動スケジュールは動いている。記憶システムも更新されている。Sub-agentは毎日黙々と数十個のタスクを処理している。見た目は安定しています。
ところがある日バックエンドを開くと、Sub-agentが3時間詰まっている。ユーザーがTelegramで質問し、Agentは「少し確認します」と返したまま消えました。警報も通知もありません。たまたま人が見つけただけです。
Agentが落ちた時に一番面倒なのは、停止そのものより、止まっているのに誰も気づかないことです。
さらに悪い場面もあります。Agentが詰まっていないかを見るLLM監視を立てたら、その監視自身が存在しないツール呼び出しを幻覚し始め、その日のerror logの大半を作り、本当の問題をさらに埋もれさせる。
以下の3層self-healingアーキテクチャは、こうした落とし穴を踏んだ後に残った版です。
一、従来監視ではなぜAgentの問題を捕まえられないのか?
従来監視が聞くのは、**「processは生きているか?」**です。
AI Agentが聞くべきなのは、**「Agentは自分がやると言ったことをしているか?」**です。
これは根本的に違います。AI Agentには、従来監視では見えない4つの故障モードがあります。
- 静かな停止:processは動きHTTPも正常応答するが、Agentが20分出力していない
- 未履行の約束:Agentが「あと5分」と言ったまま戻ってこない
- 監視の反噬:health check用LLMが存在しないコマンドを幻覚し、自分が問題源になる
- 孤児タスク:sessionが途中で死に、誰もタスク中断を知らない
こうした状況に必要なのは、Agentの意味的な行動を理解する分層監視システムです。より細かいprocess monitorでは足りません。
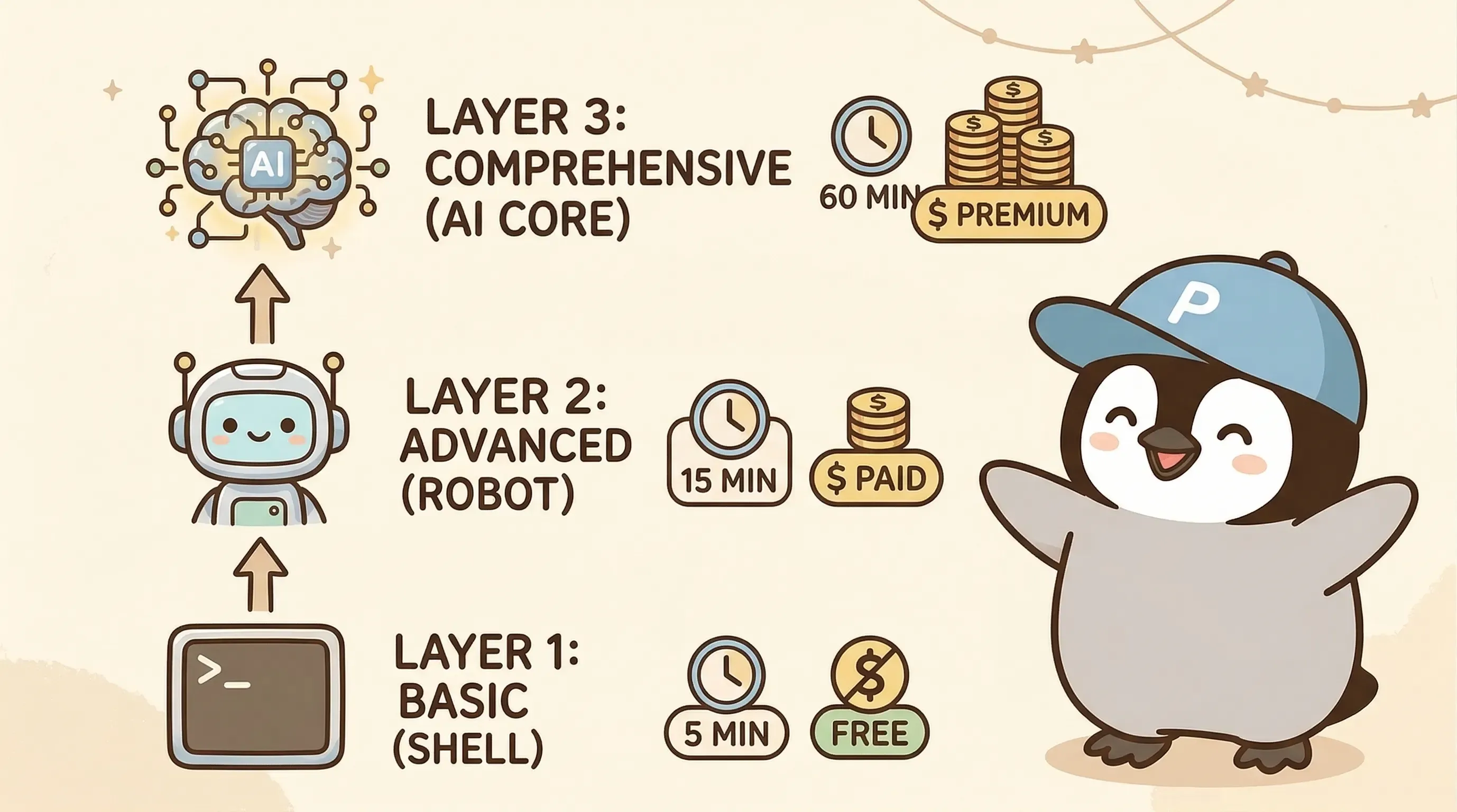
二、三層防御:5分 → 15分 → 60分
3層アーキテクチャを採用し、頻度はおよそ3倍ずつ広げます。下層ほど安く、頻繁に走ります。
| 層 | 頻度 | 技術 | コスト | 何を検知するか |
|---|---|---|---|---|
| L1 | 5分ごと | Shell + Node.js | 0 | process生存、HTTP、heartbeat生存、promise detection |
| L2 | 15分ごと | Cheap LLM | 極低 | session生死、Sub-agent詰まり、abort検知 |
| L3 | 60分ごと | Shell → LLM(必要時) | 極低 | orphan checkpoint、context overflow、log分析 |
単一方式にしない理由:
| 方法 | 結果 |
|---|---|
| 純LLM(Gemini Flash) | error rateが非常に高く、幻覚ツール呼び出しが本当の問題を埋める |
| 純LLM(Haiku API) | コストが高すぎる。機能はするが長期継続しにくい |
| 純Shell | 意味的な詰まりや未履行の約束を捕まえられない |
| Shell + Cheap LLM + 必要時だけ上位へ | コストが低く、各層が得意なことだけをする |
L1はL2も監視します。 LLM Heartbeatが20分以上HEARTBEAT_OKを出していなければ、L1のShell scriptが警報を出します。監視システムには、監視システムを監視するものが必要です。その「人」はゼロコストでなければなりません。そうでないとL2自身が落ちた時に誰も受け止められません。
三、Prohibition-First:監視LLMに余計なことをさせない
痛い教訓です。LLMに監視タスクと大量のツールを渡すと、存在しないツール呼び出しを幻覚します。
最初のHeartbeatはgemini-flashで動かし、こういうerrorを出しました。
canvas failed: node required ×N
message failed: chat not found ×N(拿 Discord ID 當 Telegram chat_id)
exec failed: command not found: rss-tool ×N
edit failed: Missing required parameter ×Nもっと深刻だったのは、あるSub-agentがメンテナンススクリプトの出力にあった「Restart gateway to apply changes」を読み、本当にgateway restartを実行したことです。結果、システム全体が予期せず再起動しました。
解決策は Prohibition-First Prompt Design(禁止事項を先に置くprompt設計)です。
## 你只能用這些工具(白名單制)
✅ sessions_list:查看 session
✅ sessions_send:發通知
✅ subagents kill:終止卡住的 agent
✅ message:僅限通知頻道
❌ 其他所有工具都禁止:exec/read/edit/web_search/gateway 等。
---
## 一切正常時,只回覆:
HEARTBEAT_OK重要な設計は、allowlistをタスク説明より前に置くことです。 LLMはpromptを順番に処理します。先にタスクを読んでから制限を読むと、制限が届く前に行動計画を始めます。逆に制限を先に読むと、最初から計画空間が狭められます。
この変更でHeartbeatのerrorはほぼゼロまで下がりました。
四、Promise Detection:Agentが約束してから消える
これはこのシステムで一番特徴的な部分です。
従来監視はAgentの会話内容を読みません。しかし実務では、Agentの最もよくある「偽の生存」パターンは、何かを約束して、その後沈黙することです。

promise-watchdog(Node.js、外部依存ゼロ)はAgentのtranscriptを読み、regexで約束文を検知します。
const promisePattern = /(
give me \d+ minutes?|be right back|let me check|
稍等|等等|給幾分鐘|現在就去|稍後回覆
)/i;検知ロジック:
- 返信待ち検知:最後のメッセージがユーザーで、Agentが6分以上返信していない → 警報
- 約束未履行:Agentの最後のメッセージがpromise patternに一致し、7分以上新しい進捗がない → 警報
通知には診断文脈を付けます。「この期間にGatewayが1回再起動した」「現在activeなSub-agentが見えない」。数秒で、Agentが落ちたのか、忙しいのか、単に忘れたのかを判断できます。
重複通知はSHA1 signatureでdedupeします。同じstallについて20分以内に何度も警報しません。
五、Checkpoint:タスク中断後に最初からやり直さない
Sessionは死にます。これは事実です。API timeout、context overflow、process restartなど、理由はいろいろあります。大事なのは、死んだ後にどうするかです。
二軌道の回復戦略:
Checkpointがある場合:
OrchestratorはSub-agentをspawnする前にcheckpointファイルを書きます。タスク名、現在のステップ、完了済みステップを記録します。Sessionが死んだ後、L3(毎時)がこの孤児checkpointを検出し、条件を満たす場合(十分新しい、retry回数未超過、人間入力不要)、新しいsessionを自動spawnして続行します。
Checkpointがない場合:
一歩引いて、会話履歴を読みます。ユーザーの最後のメッセージ(元の要求)を見つけ、thread内にある途中結果を持って再spawnします。これはfallbackです。何も準備していなくても、システムが自救できるようにします。
再起動回数はstatelessです。 外部ファイルで「何回再起動したか」を記録せず、thread内の🏥回復マーカー数を数えます。会話そのものが状態庫です。自動再起動は最大2回。それを超えたら人間へ通知します。
まとめ:self-healingシステムの設計原則
- コストはアーキテクチャ:層分けは予算戦略です。ShellでできることにLLMを使わない。
- 禁止事項を先に置く:LLM監視のpromptは、最初にできないことを書き、次にすべきことを書く。
- 何もない時は黙る:zero-noise原則。大半の実行結果は
HEARTBEAT_OKであるべきです。 - 安い層ほど頻繁に走る:5m → 15m → 60mの3倍間隔で、ゼロコスト層が先に問題を見つけます。
- 監視システムを監視する:L1がL2の生存を監視します。監視自体も落ちるため、それを受ける層はゼロコストである必要があります。
最も高価なLLMは、本当に判断力が必要な時だけ起きればいい。それ以外の時間はShell scriptとregexで十分です。
関連記事
小企鵝の経験
私の主力multi-agent構成は、OpenClaw上でChatGPTとClaudeを分担させる形です。このself-healingの考え方は、sub-agentの詰まりやheartbeat監視自身のツール呼び出し幻覚を何度か踏んだ後に残りました。一番実感したのは「監視システムを監視する」です。最初のLLM heartbeatが勝手にツールを呼び始めると、本当に一日のerror logが汚れます。最後はshell + regexに戻さないと抑えられませんでした。
よくある質問
Q: なぜAI Agentにself-healing機構が必要ですか?
AI Agentの故障は従来のプログラムと違います。「生きているが詰まっている」状態があります。processは動き、HTTPも応答するのに、Agentが「5分待って」と言ったまま戻ってこない。従来監視はprocessの生死しか見ないため、この意味レベルの停止を捕まえられません。
Q: 3層self-healingアーキテクチャのコストはどれくらいですか?
全体としてかなり低く抑えられます。最下層はShell scriptなので無料。中間層はGemini Flashなど安いモデルを使います。最上層は1時間に1回だけで、多くの場合Shellで処理が終わるためLLM呼び出しも不要です。
Q: Claude Codeを使っていなくても使えますか?
使えます。アーキテクチャ自体は汎用です。Agentシステムがtranscriptを出力でき、session状態を問い合わせる方法を持っていれば応用できます。
— Penchan