AI Agent 自我修復:三層架構讓你的 Agent 不再掛給你看
AI Agent 掛了不可怕,可怕的是掛了你不知道。本文分享從實戰中長出來的三層自癒架構——用 $0.10/月的成本,讓 Agent 自己偵測卡死、自己恢復任務、自己回報狀態。

記者:Penna | 2026-03-30 | AI 技術分享
你的 AI Agent 上線三個月了。自動排程在跑,記憶系統在更新,Sub-agent 每天默默處理幾十個任務。一切看起來很穩定。
然後某天你回來,發現一個 Sub-agent 三小時前就卡住了。用戶在 Telegram 問了一個問題,Agent 回了「稍等我查一下」——然後就消失了。沒有任何警報。沒有任何通知。你是因為自己剛好打開後台才發現的。
Agent 掛了不可怕。可怕的是掛了你不知道。
更可怕的是:你建了一個 LLM 監控來看 Agent 有沒有卡住,結果這個監控自己開始幻覺出不存在的工具呼叫,貢獻了當天 80% 的 error log,反而把真正的問題埋得更深。
這篇文章分享我們在 14 次架構迭代後長出來的自癒系統。不是理論框架,是從 23 個實際故障案例中反覆修正的結果。
一、傳統監控為什麼抓不到 Agent 的問題?
傳統監控問的是:「進程活著嗎?」
AI Agent 需要問的是:「Agent 有在做它說要做的事嗎?」
這是根本性的不同。AI Agent 有四種傳統監控看不到的故障模式:
- 靜默卡死:進程在跑,HTTP 正常回應,但 Agent 已經 20 分鐘沒有輸出
- 承諾未兌現:Agent 說「給我五分鐘」,然後再也沒回來
- 監控反噬:你的健康檢查 LLM 開始幻覺出不存在的指令,自己變成問題
- 孤兒任務:Session 中途死了,沒有人知道任務中斷了
要解決這些問題,你需要的不是更好的 process monitor,而是一個理解 Agent 語義行為的分層監控系統。
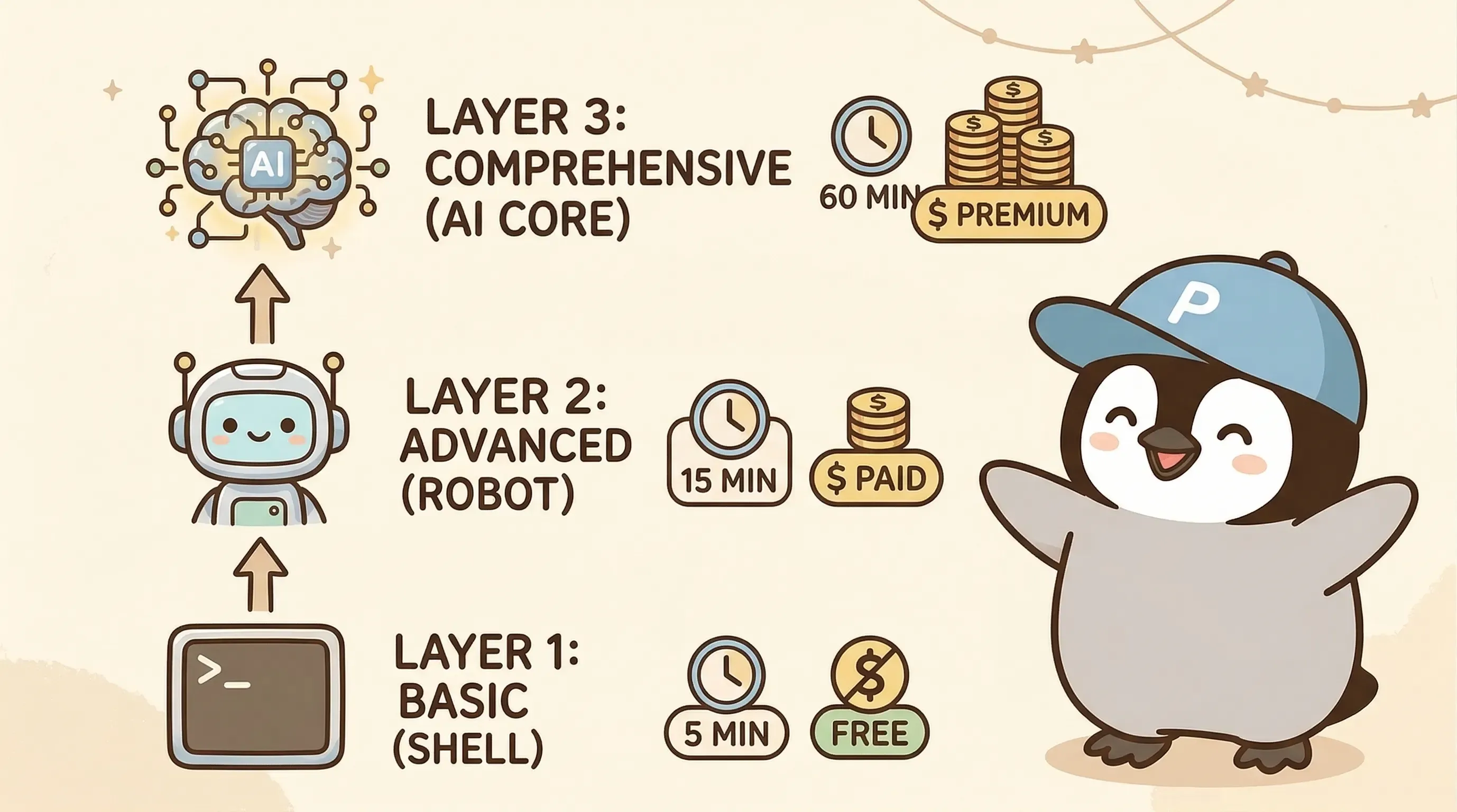
二、三層防護:5 分鐘 → 15 分鐘 → 60 分鐘
我們的解法是三層架構,頻率呈 3 倍遞增。越底層越便宜,跑越頻繁:
| 層 | 頻率 | 技術 | 月成本 | 偵測什麼 |
|---|---|---|---|---|
| L1 | 每 5 分鐘 | Shell + Node.js | $0 | 進程存活、HTTP、心跳存活、承諾偵測 |
| L2 | 每 15 分鐘 | Cheap LLM | ~$0 | Session 死活、Sub-agent 卡死、abort 偵測 |
| L3 | 每 60 分鐘 | Shell → LLM(按需) | ~$0.01 | Checkpoint 孤兒、Context 溢出、Log 分析 |
為什麼不全用 LLM?為什麼不全用 Shell?我們都試過了:
| 做法 | 結果 |
|---|---|
| 純 LLM(gemini-flash) | 80%+ error rate,幻覺工具呼叫淹沒真正問題 |
| 純 LLM(haiku) | 每月 $200+,功能正常但太貴 |
| 純 Shell | 抓不到語義卡死和承諾未兌現 |
| Shell + Cheap LLM + 按需升級 | $0.10/月,各層只做自己擅長的事 |
L1 還負責監控 L2。 如果 LLM Heartbeat 超過 20 分鐘沒出現 HEARTBEAT_OK,L1 的 Shell 腳本就會發出警報。監控系統需要有人監控監控系統——而那個「人」必須是 $0 的。
三、Prohibition-First:讓監控的 LLM 不要幫倒忙
我們學到最痛的一課:給 LLM 一個監控任務和一堆工具,它會幻覺出不存在的工具呼叫。
第一版 Heartbeat 用 gemini-flash 跑,結果一天之內產生了這些 error:
canvas failed: node required ×4
message failed: chat not found ×4(拿 Discord ID 當 Telegram chat_id)
exec failed: command not found: rss-tool ×1
edit failed: Missing required parameter ×1更嚴重的是:有一個 Sub-agent 讀到維護腳本的輸出——上面寫「Restart gateway to apply changes」——它就真的去執行了 gateway restart,導致整個系統非預期重啟。
解法是 Prohibition-First Prompt Design(禁制前置設計):
## 你只能用這些工具(白名單制)
✅ sessions_list — 查看 session
✅ sessions_send — 發通知
✅ subagents kill — 終止卡住的 agent
✅ message — 僅限通知頻道
❌ 其他所有工具都禁止:exec, read, edit, web_search, gateway...
---
## 一切正常時,只回覆:
HEARTBEAT_OK關鍵設計:白名單放在任務描述之前。 LLM 是順序處理 prompt 的——如果先讀到任務再讀到限制,它會在限制到達之前就開始規劃動作。反過來,先讀到限制,它的規劃空間從一開始就被框住了。
這個改動讓 Heartbeat 的 error 降到了接近零。
四、承諾偵測:Agent 說「等我」然後消失了
這是整套系統中最獨特的部分。
傳統監控不會去讀 Agent 的對話內容。但我們發現,Agent 最常見的「假活著」模式就是:它承諾了某件事,然後靜默了。

我們的 promise-watchdog(Node.js,零外部依賴)會讀取 Agent 的對話紀錄,用 regex 偵測承諾語句:
const promisePattern = /(
give me \d+ minutes?|be right back|let me check|
稍等|等我|給我幾分鐘|我現在就去|稍後回覆
)/i;偵測邏輯:
- 待回覆偵測:最後一條訊息是用戶發的,Agent 超過 6 分鐘沒回 → 警報
- 承諾未兌現:Agent 最後一條訊息符合承諾 pattern,超過 7 分鐘沒有新進度 → 警報
通知會附上診斷脈絡:「這段期間 Gateway 重啟了 1 次」「目前看不到活躍 Sub-agent」——幫你在 5 秒內判斷是 Agent 當機、在忙、還是單純忘了。
重複通知用 SHA1 簽章去重,同一個 stall 在 20 分鐘內不會重複告警。
五、Checkpoint:任務中斷了不用從頭來
Session 會死。這是事實。API timeout、context overflow、進程重啟——原因百百種。問題是:死了之後怎麼辦?
我們的做法是雙軌恢復:
有 Checkpoint 的情況:
Orchestrator 在 spawn Sub-agent 前寫一份 checkpoint 檔案,記錄任務名稱、目前步驟、已完成的步驟。Session 死了之後,L3(每小時)會掃描到這個孤兒 checkpoint,如果符合條件(< 1 小時、重試 < 2 次、不需要人類輸入),就自動 spawn 新的 session 繼續。
沒有 Checkpoint 的情況:
退一步——直接去讀對話歷史。找到用戶最後一條訊息(原始需求),帶著 thread 裡已有的部分結果,重新 spawn。這是 fallback,但它確保了即使什麼都沒準備,系統也有辦法自救。
重啟計數是無狀態的。 不靠外部檔案記錄「重啟了幾次」,而是數 thread 裡的 🏥 恢復標記數量。對話本身就是狀態庫。最多 2 次自動重啟,超過就通知人類。
總結:自癒系統的設計原則
- 成本即架構 — 層級劃分不是工程選擇,是預算策略。能用 Shell 做的不要用 LLM
- 禁制前置 — LLM 監控的 prompt,第一段寫它不能做什麼,不是它應該做什麼
- 沒事不說話 — 零噪音原則。95%+ 的執行結果應該是
HEARTBEAT_OK - 越便宜跑越頻繁 — 5m → 15m → 60m 的 3 倍遞增,讓 $0 的層最先發現問題
- 監控監控系統 — L1 監控 L2 的存活。監控本身也會掛,誰來監控它必須是 $0 的
最貴的那台 LLM?它只在真正需要判斷力的時候才醒來。其他 99% 的時間,Shell 腳本和 regex 就夠了。
完整架構、可執行腳本、prompt 模板、23 個故障案例 → GitHub: p3nchan/agent-self-healing
本文基於 14 次架構迭代和 23 個實際故障案例的運維經驗撰寫。所有 pattern 和 script 以 MIT 授權開源。
小企鵝阿批 Penchan